Prompting Sucks (And What We Can Do About It)
Prompting sucks. If you have spent any time working with LLMs, you already know this.
It is not just that prompting is difficult - it is fundamentally broken as an approach to working with AI. It is brittle, model-specific, and endlessly repetitive.
Here is why we need to move beyond prompting, and what we can do about it.
The problem with prompting
Prompting is situational and brittle. A carefully crafted prompt that works perfectly can completely break with seemingly minor changes to the input.
If you have only used more expensive models from OpenAI, you might not have experienced this acutely. But try working with cheaper models, and you will quickly discover just how fragile prompting can be.
This brittleness is compounded by the fact that prompts are highly model-specific. You cannot simply take prompts designed for one model and expect them to work with another. It feels like trying to use a horse to pull an express train, or a steam engine to power a spaceship. It is not a good fit.
The result is endless tweaking and repetition, where you are going around in circles without knowing if you are actually making progress.
We have been here before
Working with LLMs today feels remarkably similar to the early days of computing when people punched cards for a living.
The parallels are striking:
-
Machine specificity: Just as each manufacturer had their own punch card standard (80 holes for IBM, 90 for Remington Rand), each LLM requires its own specific prompt engineering process.
-
Specialist knowledge: prompts, like punch cards, are indecipherable to the non-programmer. They might be written in natural language, but seemingly spurious details matter hugely to the outcome. These have been painstakingly discovered through iteration and their removal could break the system.
-
Slow feedback loops: While we are not waiting hours for results like in the punch card days, the process of iterating on prompts is still painfully slow and inefficient.
The false promise of prompt engineering
Companies are now hiring “Prompt Engineers”. They are training their developers in better prompting. This is treating the symptom, not the cause.
Creating a new job title around a broken paradigm will not fix the underlying problems. We do not need the 20th century version of punchcard operators. We need to fundamentally rethink how we interact with AI systems.
When you are stuck in a particular way of doing things, it can be hard to imagine alternatives. Even the most fanciest computers in people’s imagination, such as the BATCOMPUTER, were still just expensive and futuristic looking punch card machines.
Moving beyond prompting
The answer is to look at our history. We need to take the lessons learned from software engineering’s evolution and apply them to working with AI.
The solution is not to get better at prompting - it is to move beyond it. Three key principles will help us move forward:
- Abstraction: Moving beyond raw prompts to higher-level concepts
- Automated Testing: Ensuring reliability at scale
- Auditing: Understanding what our systems are actually doing
Abstraction
Just as we moved beyond writing raw machine code, we need to move beyond raw prompting through the use of abstractions.
Abstraction eliminates complexity. From assembly language to high-level programming languages, each layer of abstraction added to software development through new tools made programming more accessible and productive. The same pattern needs to emerge for working with AI systems.
The power of abstraction in computing history
Here is a brief journey through how successive layers of software abstraction made things simpler. At the lowest level, we had machine code - raw numeric opcodes that the CPU executes:
48 65 6c 6c 6f 2c 20 57 6f 72 6c 64 21 0a ; "Hello, World!\n"
b8 01 00 00 00 ; mov rax, 1 (write)
bf 01 00 00 00 ; mov rdi, 1 (stdout)
48 be 00 10 40 00 00 ; mov rsi, msg
00 00 00
ba 0e 00 00 00 ; mov rdx, 14 (length)
0f 05 ; syscall (write)
b8 3c 00 00 00 ; mov rax, 60 (exit)
bf 00 00 00 00 ; mov rdi, 0 (status)
0f 05 ; syscall (exit)Structured assembly gave us named sections and labels:
section .data
message db "Hello, World!", 0xa
len equ $ - message
section .text
global _start
_start:
mov rax, 1 ; write
mov rdi, 1 ; stdout
mov rsi, message
mov rdx, len
syscall
; Exit program cleanly
mov rax, 60 ; syscall: exit
xor rdi, rdi ; exit code: 0
syscall ; invoke the syscallC freed us from thinking about registers entirely:
#include <stdio.h>
int main() {
printf("Hello, World!\n");
return 0;
}Shell scripts stripped away even more complexity, though this level of abstraction is not always appropriate - it depends on your needs. For system administration tasks, shell scripts provide a good level of control:
echo "Hello, World!"Abstractions in the AI world
The AI world is about to go through this same evolution - moving from raw prompts to higher-level abstractions that hide complexity while preserving control over what matters. The crucial advantage of abstractions is that they hide incidental details that almost every programmer could safely ignore. We need to find the same type of abstractions for AI. What details can most AI developers leave to their tools?
To answer this question, I spoke with over a dozen developers and technical leaders building AI systems in early 2025. Their experiences, combined with my own experiments on toy projects, inform the examples below of how teams are trying to build or use abstraction layers for AI apps and how those approaches are working out.
Langchain
Langchain is an incredibly popular library that abstracts away prompt engineering and LLM interactions into reusable components. I tried Langchain for a while in 2024, working with its chains and agents that pipe model calls together. The chains let you sequence operations like “summarize this text, then answer questions about it”, while agents can dynamically choose which tools to use based on the task.
However, I still found myself writing prompts in Python and it was a struggle to see what was happening under the hood. The demos were cool, but when I tried building real features, the abstractions were not flexible enough. The wrong abstraction is worse than no abstraction at all, so I ended up moving to a simpler custom solution using APIs natively that worked better for my use case.
Others reported similar experiences, but I am keen to hear from you if your recent experience has been different.
DSPy
I then spent some time working with DSPy, a framework that brings machine learning principles and terminology to LLM development. DSPy’s key abstraction innovation is the Signatures system - clean interfaces that let you declaratively specify the inputs and outputs of each component. For example, you can define a Signature that takes a question and returns an answer, or one that takes a document and returns a summary.
Under the hood, DSPy compiles these Signatures into optimized prompts. The real step forward for me is the abstraction of the prompt itself. It uses various optimisers to choose the most optimal examples for each prompt, focusing on optimising against a metric, described as similar to a loss function in the documentation.
What I found most valuable was the ability to compose pieces like regular functions while maintaining full control over data flow. The ability to define a core metric and then programmatically optimize the examples sent to the prompt is a powerful way to optimize the prompt. I could measure quality and auto-tune my system for a model using an increasing number of examples.
I did not end up building a full production system with DSPy, but I saw enough potential to be excited. It is not perfect - it is only implemented in Python and ports to other languages were a long way behind when I tried them last year. It did however feel like a real step forward in abstracting away the tedious parts while preserving control over what matters, albeit more of a proof of concept than a production-ready system.
Visual Tools
Langflow and Flowise let you build chains and agents through a visual interface. They aim to make LLM application development more accessible by providing drag-and-drop interfaces for connecting components. This abstracts the textual code without removing any of the concepts. While these tools can speed up prototyping, they could face the same challenges as Langchain.
The abstractions do not hide away knowledge. You still need to know how all the pieces work and how to assemble them. You still need to know how to prompt, and you can get stuck when things go wrong. This type of abstraction might be useful for some, but I see it as more of a gimmick than a real step forward in my own productivity.
Finding the Right Level of Abstraction
None of these abstractions are perfect. The right abstractions for AI will emerge through continued experimentation and real-world usage. Different use cases will require different abstractions. What works for a chatbot may not work for a document processing pipeline. We will likely see a rich ecosystem of options emerge. That can only be a good thing.
I believe that the exact text of prompts will become incidental detail for most applications. Just as we do not care about the specific assembly instructions generated by our code, we should not need to care about the exact words used to prompt the model. What matters is the interface - what goes in and what comes out.
This is why I am excited about frameworks that abstract away prompt engineering while preserving control over the inputs, outputs and evaluation metrics that actually matter for the application.
The right abstractions will make prompting as obsolete as punch cards. Code is a liability, and prompts are no different.
More soon
More on automated testing and auditing in a future update to this post.
More articles
Coding with AI: How To Do It Well And What This Means
I am shipping AI-first production code every day. Not experimental features. Not throwaway prototypes. Real, deployed, mission-critical code powering Cherrypick’s tens of thousands of users.
Social media overflows with “vibe coding” demonstrations. These flashy but superficial examples show AI apparently conjuring perfect code in seconds. The reality of professional AI-assisted development runs much deeper. Real production work with AI is messier, more nuanced, and demands rigorous thinking, but very effective.
This is not about magical code generation. It is about a new way of thinking about development. It requires substantial real-world development experience to do well: the onus is upon those of us with this experience to teach the next generation how to harness these tools effectively.
This is how I am doing it, what it all might mean, and how we can help others find the way.
Read moreHow to Build a Robust LLM Application
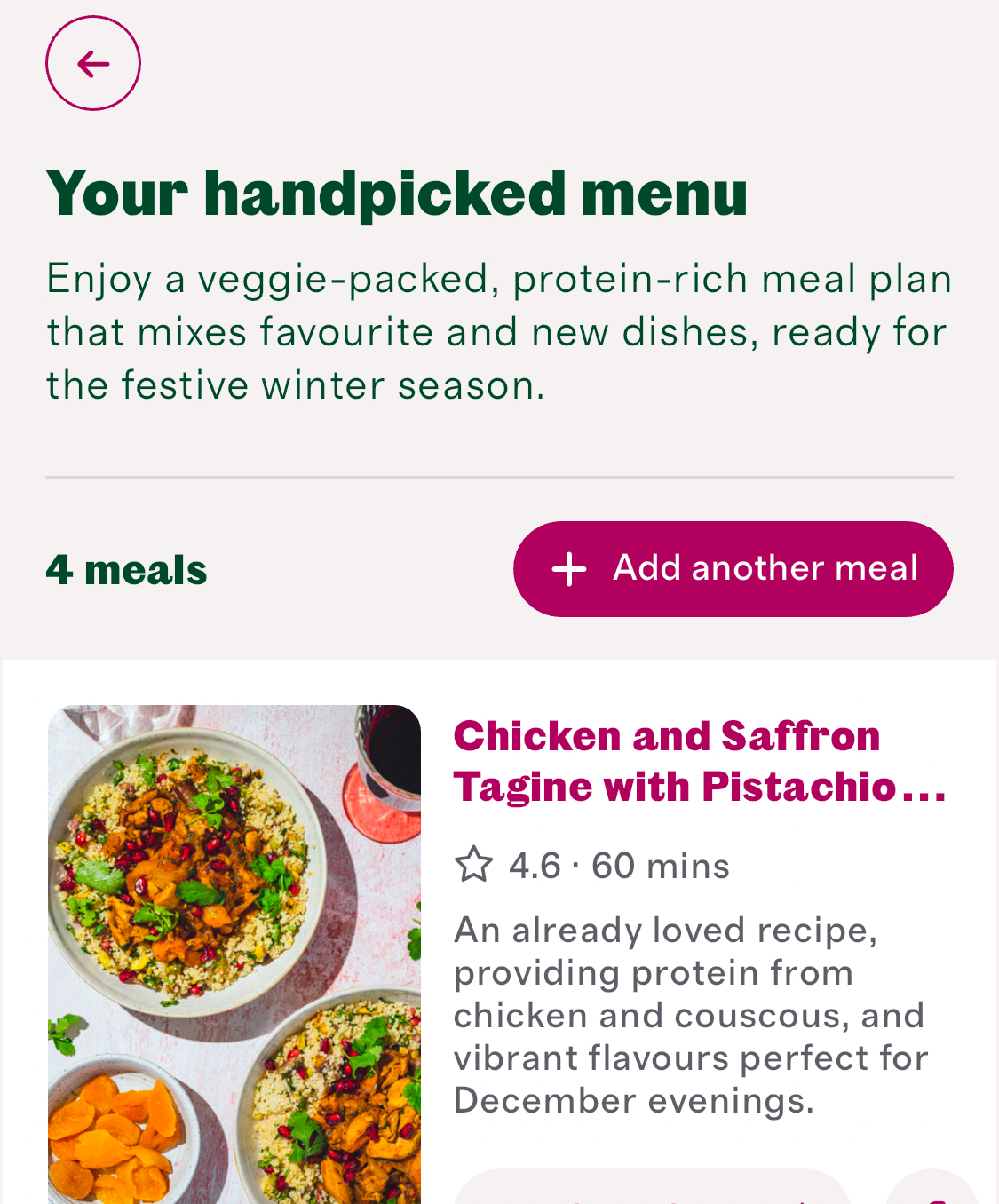
Last month at Cherrypick we launched a brand new meal generator that uses LLMs to create personalized meal plans.
It has been a great success and we are pleased with the results. Customers are changing their plans 30% less and using their plans in their baskets 14% more.
However, getting to this point was not straightforward, and we learned many things that can go wrong when building these types of systems.
Here is what we learned about building an LLM-based product that actually works, and ends up in production rather than languishing in an investor deck as a cool tech demo.
Read more