C++ is fast. It’s a good fit for games. It’s certainly faster than Ruby. However, there’s a better fit for game development. It’s called C.
This isn’t an April Fool’s joke. Look at what happened to the Sol Trader history system when I ditched the slow C++ version and rewrote it in optimised C. The line count is also about 20% reduced.
C++ code can be fast, but the way C++ is commonly used and the language features that it promotes can get in the way of this goal. Here are a few things I’ve learnt about C++ that are essential for anyone to know who wants to write modern performant code.
Memory access is slow
In case you hadn’t realised: compared to your CPU, your memory is slow. Very slow. It’s probably the thing that’s most holding your CPU back right now.
Memory has been gradually increasing in speed over the last few decades, but at 10% of the rate of CPU speed:
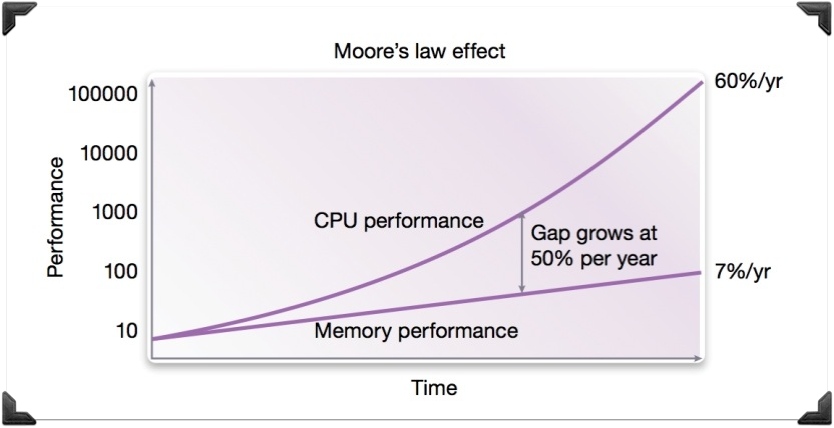
Memory cache misses cause the CPU to stall, losing several hundred cycles each time it happens. Every year, cache misses become a more and more significant cause of CPU slowdown.
With the previous version of the history generation, using classic object oriented patterns, my data was all over the place. I had hundreds of little objects all encapsulating their own data, using virtual method calls to access tiny pieces of it.
I moved to arrays of values, storing references to other objects via indexes everywhere. I moved all the string processing right out of the generation engine, so that the engine was only dealing with small data structures of perhaps 20-30 bytes at a time.
Virtual function calls are slow
A virtual function is one that changes it’s behaviour depending on the type of the object. For example, if we use an interface in C++, we create an abstract class with some virtual functions attached to it. We then derive our class from this interface, passing pointers of the interface type around our program. When our program calls the interface function, the program is able to work out which method to call on the derived object, based on extra information that’s kept in our object.
So far, so good. Except virtual functions are slow for the same reason that the memory is slow. With virtual methods, the right method to call can only be decided at run time, and there’s normally one or two cache misses for these method calls. The compiler is constrained about what it can do to make this quicker. It might not seem like much, but it stacks up for inner loops.
Back in 2002, when I was working in the games industry, I lambasted the PS2 to my fellow AAA games developers for not even supporting virtual pointer tables, meaning that virtual functions were impossible. In deriding the platform I showed my ignorance about the speed trade offs that smarter people than me were making. It turns out that the constraints of the PS2’s architecture changed the face of games development for the better.
A few virtual calls aren’t going to massively slow down a codebase. However, my code was a mass of tiny virtual calls for trivial operations. Parts of my code were iterating over every entity in the game with at least three or four chained virtual function calls each time!
In the new version of the code, I cut out all the virtual methods completely, sticking to bare C++ method calls. I inlined a lot of these, leaving the game with fewer longer methods but without the need for the CPU to constantly be jumping around to figure out what to do.
Templates are slow (to build)
Templates were introduced to C++ in order to help make parts of the code generic with respect to type. For example, the supplied vector type in C++ is a template type, meaning that we can store multiple different types of objects in the same data structure. This allows us to seperate two concerns: the way the object is stored and how it works, which partitions complexity for our minds.
Templates reduce the number of lines of code in our programs. They are harder to understand when reading them later, but the bigger disadvantage is that they slow down build time. The compiler has to effectively copy all the code each time for each template and do a lot of processing in order to produce efficient executables out of them.
By cutting out all the templates from my code (including all uses of the C++ Standard Template Library), I’ve cut down the full build time of the entire game to about 4 seconds. With a debug loop as short as this, I barely have time to sip my tea before I’m testing the code I just wrote, and I can change headers without having to wait 10 minutes for a new build to compile.
Encapsulation can be unhelpful
Encapsultation is the packing of functions and data into one component. It is one of the fundamental concepts behing Object Oriented programming.
Much of encapsulation in C++ (and other OO languages) is promoted through the use of classes with private members to hide data from outside code.
Promoting encapsulation is held up as a pillar of good code design. However, I think we might be doing encapsulation wrong. I don’t think encapsulation should be at the class or method boundary, but at the data boundary.
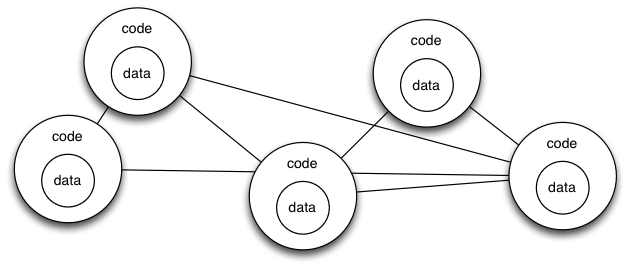
Essentially I’m advocating a switch from this style of coding:
To this style:
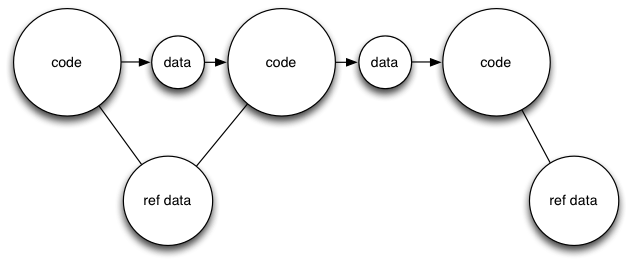
It’s important to get our architecture right. We encapsulate concepts in the correct sections of our program and ensure data flows well through the various pieces. If we use simple value objects (perhaps arrays of data) as the handoff between different sections of our program, calling methods that transform data between different types, then our code becomes more isolated and easier to reason about. It’s also far easier to parallelise.
Incorrect encapsulation is worse than no encapsulation at all. Hiding data behind code limits what the calling code can do. Those constraints can be helpful, but they can also hinder us. If we get the architecture right and use data structures to provide bounded contexts to our code, rather than layers of method abstraction, then we have less need to hide our data from others.
By rearchitecting my application to not require callbacks at all, I’ve made it simpler to test and debug. There’s less code reuse, but inevitably the concepts I thought were duplicated were actually subtly different. I’m also treating the data in batches, looping through arrays of small amounts of data rather than arrays of objects. Rather than one big loop bouncing up and down the layers of abstraction for each object (exacerbating the method call overhead, which is further increased if we are using virtual methods), I have multiple loops doing one small stage of data transformation each time.
There are no methods in classes: it’s all public structs and functions. I still have encapsulation, because each stage of data transformation is distinct from the others, but I’ve no need to hide my data behind code.
Summary
There are some bits of C++ I find useful. Operator overloading is helpful to clean up verbose code, for example. I still compile my ‘mostly C’ code using a modern C++ compiler.
It’s the paradigms that C++ promotes and supports through its language features that aren’t for me, and I’ve doubled the speed of my code as a result.
More articles
Why AI Swarms Failed Me: The Toyota vs Ford of Software Development
AI swarms are not faster. They create massive cognitive load, produce duplicate code, and optimise for the wrong thing entirely.
I spent a few hours experimenting with running four Claude instances in parallel to build a personal knowledge management system. It was a deliberate test to push PRD-driven development to its logical extreme and see if parallelisation could work. The result? A completely unusable codebase, some valuable lessons, and unexpected insights about the difference between manufacturing cars and building software.
Read more →The Job Is Not To Build
Startup CTOs or founding developers are the first technical people in the business. It is natural to think your job is to write code and build software. This is backwards.
Your first job is not to build software. Your role is to use your technical expertise to help the startup figure out fast if you have a valid solution to a compelling problem, and then a valid product for a big enough market.
You might do this through building software, but you might not need to.
Here is a story of how I did this wrong, and how you can do it right.
Read more →Ealdorlight: A Kickstarter retrospective

It’s now been over three months since the end of the Ealdorlight Kickstarter campaign. I’ve deliberately been taking some time to think and learn from the fact that it didn’t reach the target, and to work out what to do next. Frankly, I was pretty upset that the campaign didn’t make it, and it’s taken a while to get over it.
It’s also taken a while to think through the campaign properly. Some things are obvious in hindsight, and others less so. A lot of post-Kickstarter analysis feels like a stab in the dark. Nevertheless I’ve given it a lot of thought, and these are my best guesses for why I think Ealdorlight’s Kickstarter failed:
Read more →Ealdorlight's Kickstarter is live at 4pm today

The sixth of June is a significant day for me personally. In 2004, I spent the entire of the day in hospital. I remember the 60th anniversary commemorations of D-day on the TV in the background, as I sat beside my wife, in labour with our first child. I became a father an hour after midnight on the 7th June; my son becomes a teenager tomorrow.
Twelve years later, in 2016, I spent the entire of 6th June glued to Steam watching and waiting whilst my first game Sol Trader was released to the world. This was a career dream come true: since I started programming at six years old I’d always wanted to create and ship my own games. Sol Trader’s release was ultimately a painfully formative experience for me, which I wrote about at the time and was interviewed about recently in GamesIndustry.biz.
Over the last year, I’ve been keeping busy doing two things. One is to support Sol Trader as much as I can with countless updates and patches. I’ve also been very busy working on a new game, Ealdorlight, a medieval RPG-style take on Sol Trader’s mechanics, with turn-based combat, realistic damage and great graphics. I announced Ealdorlight in March and demonstrated it at Rezzed, strengthening my hope that the idea was a good one.
I decided fairly early on that I wanted to take Ealdorlight to Kickstarter. Sol Trader’s successful Kickstarter was a brilliant experience. The Kickstarter community is one of the kindest, most positive on the Internet. I also needed funding for this game: Sol Trader was self-funded through many long evenings and contracting work, and for Ealdorlight I need a bigger team to realise the vision. It’s built in Unreal Engine 4, which simultaneously saves me loads of development time and means I need a bigger team to pull off the realistic art style I’ve gone for.
As time came near to launch, the first anniversary of Sol Trader’s released seemed an appropriate day to launch the campaign. So today, 6th June 2017, I will spend the entire day glued to Kickstarter as my campaign goes live at 4pm today.
Visit Ealdorlight’s Kickstarter Campaign

There’s plenty more about Ealdorlight on the campaign - head over there and read all about it! A huge amount of work has gone into it, and I’m very grateful for all the support and help I’ve received from the team I’ve put together, and for friends and family who have given me endless encouragements and feedback.
This post is a little earlier than 4pm so that you can watch it go live if you want. Earlier backers get lower edition numberings on some of the rewards, so you might want to be there from the start!
Read more →How Ealdorlight's story stands out

As we head towards the Kickstarter campaign launch on June 6th, I want to talk a little about the story behind Ealdorlight works.
The basic story stays the same for each game: you are discovered wandering through a remote village at a young age, and realise your destiny is to overthrow the King. However, like in Sol Trader, every person you meet is randomly generated. This means that your real identity will be different every time, and you’ll have to discover it all over again every time you generate a new game.
Handcrafted story in a random world
The trick is layering a great story on top of a generated world with random characters. Building empathy with the main character and his family when all characters are generated is hard, and hinges around being able to hook the story in at the right moments.
My plan is to write plenty of tightly connected story arcs that are triggered on events that happen during history generation. These will in turn trigger future quests the player can undertake. Not all story-arcs will appear in every game: it will depend on how the history generation goes. I will constrain things such that there is always a route through the game, and that players always have a way to overthrow the King, even if that might be easier or harder depending on the starting setup. These story-arcs then should interact with each other, hopefully producing a unique path through the game.
Identity
Ealdorlight is set within a low fantasy world, and there’s no traditional magic. The player gets more powerful through discovering key pieces of knowledge about their past. These insights into of your real past feed directly into your character’s stats, skills and abilities.
I’ve long been fascinated with identity: knowledge of who we truly are affects many areas of our lives for the better. In Ealdorlight I wanted to tell a story which takes this to an almost supernatural level. By removing the player from their birth family, they start as an entirely normal person within the world. It’s only after their early game encounter with the Ealdorlight and the discovery of their past that things begin to change.
Much more on this to come, but in the meantime, here’s a glimpse of our story’s beginning.
Ealdorlight: backstory teaser (updated)
Read more →