As the revival of interest in Cucumber continues, I’m finding that a lot more people are using Cucumber for two very different types of testing. When coaching or training, I sometimes come across QAs writing Cucumber tests like this:
Feature: Menu regression script
Scenario Outline: Check top menu does not scroll
Given I click on <link>
And I scroll down
Then the menu should still be visible at the top of the screen
Examples:
| link |
| Home |
| About |
| Products |
| Clients |
| Services |
| Company |
| Contact |
etc.I don’t use Cucumber like this… but I’ve changed the way I approach features such as these when I come across them.
How I use Cucumber
When I use Cucumber, I hold discussions with stakeholders, and I write down the results as Cucumber features, carefully avoiding too much incidental detail to help with maintainability later. These features form the initial acceptance tests for my system. I then use TDD to flesh out the functionality I need. The features end up as very useful documentation and regression testing artefacts (which can even form a user manual for the application.)
The example feature above is very different. It is an exhaustive regression test to check that the scroll option is working in all cases on every page. This example is pretty short: in reality I’ve seen extremely long Cucumber features written in this style. Note this isn’t the same as very long boring and overly detailed features: they’re running a simple scenario in many slightly different ways.
Because this is not how I use Cucumber, I used to discourage this long form style of feature writing out of hand. I’ve learnt to stop worrying… as long as it’s clear what sort of features these are and how they should be treated.
Developers: who are we to judge?
Firstly, developers: I don’t think we should be saying “you can’t write tests like this.”
Just because people are not using the tool how we might expect them to, their use of it is not invalid. It’s very tempting to say “you’re doing it wrong”, because these feature look so much like the “bad features” developers are taught to eradicate from their codebases. However, we have to understand that they’re simply using the tool for a different set of advantages it provides: it allows them to quickly run through expected functionality on a multitude of different places.
There isn’t one way to use Cucumber (or any tool) - there are only ways that give value, and ways that increase or decrease friction. We would be wise not to discount the way that others get value out of the tools we use, just because they use them in a way that we didn’t expect.
A different approach
When I see these sorts of features, rather than dismissing these features as ‘too detailed’ or ‘unmaintainable’, I ask questions about who is using these features. Who is writing them, who is reading them, and who is keeping them up to date?
Often it’s the QA people on a team who are exclusively writing with these types of tests. These are then handed on to the developers who are getting very frustrated with them. No one is clear who should be maintaining them. The developers don’t want to, and inevitably try to refactor them, which annoys the QAs as the detailed regressions they were aiming for are lost. The QAs don’t want to maintain them as they usually don’t have strong coding skills and therefore they find it hard to maintain the step code. The end result is a void of responsibility which gives rise to a mess of unmaintained code.
A good solution? Be clear about the responsibility. Move these features out of your regular BDD workflow. Create a structure a bit like this:
features/
docs/
account_management.feature
buying_products.feature
step_definitions/
...
regression/
menu_interface_checks.feature
step_definitions/
...
Have the QAs maintain all the features and step definitions under regression above, allowing them to manage their own features without conflicting with the needs of the developers. Ensure that they’re only run under controlled conditions (perhaps as a nightly build) rather than as a part of the normal BDD workflow, otherwise they’ll slow development down to a crawl.
Who should be writing features? When we’re using Cucumber from the point of view of development and documenting functionality for customers, then write the features in collaboration with developers, testers and your business people, in ‘3 amigos’ style. However, when you’re using Cucumber to effectively construct old fashioned test scripts which perform exhaustive regression testing of the application, then I can see value in this approach.
From tail end to up front: QAs to Analysts
A word of caution for QAs: the important thing is to discuss this type of test with your developers and your business people. Are we testing where the risk is? What is the likelihood of this test ever failing in practice, catching a real bug that otherwise would not have been caught? What’s the impact of such a bug? If there’s little to no risk, or little impact, then the test we are writing has very little value, and we are creating work for ourselves for the sake of it. Overtesting is a waste of time: there is a better path for QAs.
I often try to work with QAs to transition them to a role which is much more upfront than at the tail end of the process. Traditionally, QAs are thrown working (but untested) code to see if they can break it, and the more code is sent back the more wasteful the process is.
However, with BDD there’s a lot more automated testing going on. Developers are receiving their requirements direct from the stakeholders through proper communication, distilled down to clear Cucumber features. QAs should be involved in this process, working with the stakeholders, teasing out edge cases. If that sounds like a Business Analyst role to you, then you aren’t far wrong: the roles can be very similar.
The old fashioned methods of in depth regression testing using scripts can still be useful. However, thanks to the advances of BDD and Specification By Example, there’s less need for QAs to take a lead in this area. Instead of writing these tests, or God forbid clicking through them manually, they have the opportunity to take a lead in defining the scope of what’s under test and when a requirement is finished.
In summary
There’s nothing wrong with features like these in our codebase as long as we understand who they’re for, why they’ve been created, and who is maintaining them. Let’s not be quick to dismiss them, just because we’re not used to writing features in this style; but let’s also be sure they’re necessary before littering the build with brittle tests that have little value.
Do you have features like these in your code? Are you using them to drive business value, or are they clearly separate from your other features? How could they be improved?
More articles
The toolchain of dreams
Seems like yesterday people were saying that it was difficult to host Ruby apps. It was around the time people were saying “Rails doesn’t scale”, which thankfully has been proved dramatically wrong.
For a while now Ruby apps have been unbelieveably easy to run and host, especially when you’re getting started.
But it’s got even better than that in the last few months. I’ve now got a complete Continuous Delivery toolchain set up for my latest app, entirely in the cloud. It’s Continuous Delivery As A Service, and it’s dreamy. This is how to set it up, and how it works.
Source control: Github
I’m using Github for code hosting and source control. You probably are already too. Most of the other services integrate with it very well, so setting this toolchain up is so much easier if you’re using it.
Build server: Semaphore
Cloud-based build services have been running for a while now. I like Semaphore - the user interface is clean and easy to read, and it does automatic deploys of passing code:
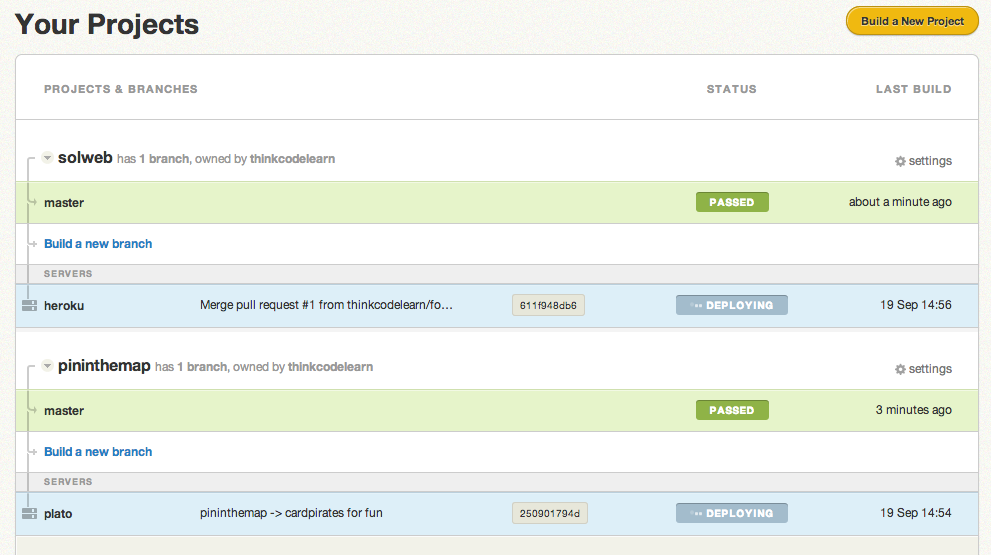
Set up Semaphore by creating a trial account, connecting it with your Github account and picking the repository you’d like to build. It automatically analyses your project for a build script so if you have a standard Ruby or Rails project you probably won’t need to configure it much.
Deployment: Heroku
If you’re using Heroku to deploy your code, set it up to deploy to Heroku. It takes a few seconds in the settings menu for your project to do so. You can also make it use a Capistrano deploy script.
Quality Analysis: Code Climate
Lastly, set up Code Climate to monitor the quality of your app’s code. Setting up Code Climate is similar to Semaphore: sign up for a trial, connect to Github, select the repository. It will automatically set up the Github commit hooks for you.
To get code coverage integration, you’ll need to install a gem, but it only takes a few minutes.
How the toolchain works
Out of the box, Github tells Semaphore to build every commit I push. If I push a branch, Semaphore builds that, too, and updates the build status of the commit so that everyone can see if the pull request is ready:
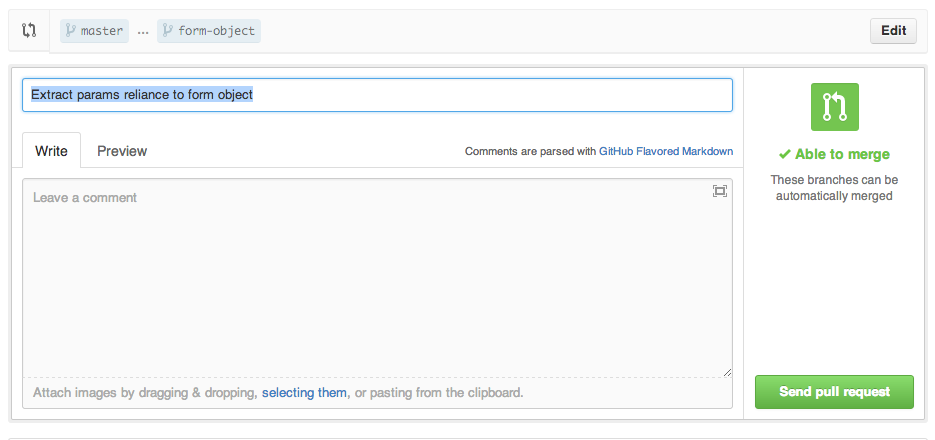
Merging code into master
When the pull request is merged, the code goes into master:
- Semaphore builds the master branch. If the tests pass, the code is deployed to Heroku.
- Code Climate automatically gets notified by Github and checks to see whether coverage has improved or decreased, whether I’ve introduced any Rails security problems, or whether my code is bad:

Logging
Builds, deploys and Code Climate notifications are all automatically posted to Hipchat, so I get a log of everything that’s happened without being inundated with emails:
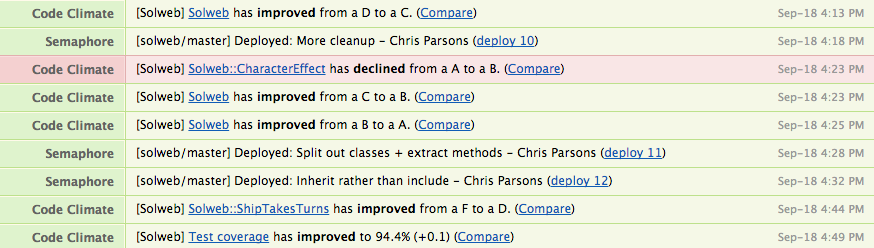
Just set up a Hipchat account, get a Room API key from the settings page, and plug that into Github, Code Climate and Semaphore. Done.
The dream toolchain
This is how you use this toolchain:
$ git pushEvery time I push some code, it’s checked carefully, and monitored for quality and security holes. The tests are run and coverage reports are generated and presented nicely. If all the tests pass the code immediately gets deployed to production, and all of this activity is reported and logged in one central place.
This is the future. It really doesn’t get much better.
Time is valuable: and this didn’t take long
This took me about 40 minutes to set up. 30 minutes of that was fiddling with the settings of the various tools: but actually leaving them all set to default does the right thing for me in all cases. Most of the tools simply connect to your Github account to set up all the access controls and keys for you.
The cost
For one project, this incredible toolchain will cost you the following:
- Github: $7 a month for the micro plan
- Semaphore: $14 a month for the solo plan
- Code Climate: $24 a month for the solo plan
- Hipchat: Free for one room
- Heroku: Free for a one dyno app.
That’s $45 a month. That’s next to nothing for such an amazingly powerful toolchain. Plus if you run more than one project, the per-project cost decreases dramatically.
I used to run one server to host one Rails app for $140 a month, for years, with no build server, deployment or code metrics built into the toolchain. Today I pay half that for a much more sophisticated setup.
Admittedly, the hosting costs with Heroku will go up once your app becomes popular, but this is a good problem to have, and at that point you shoud have the cash to invest in a chef-based cloud server deployment solution. I run one of those for an old SaaS service I run to keep costs down. It’s still very easy to connect a different deployment strategy in to this toolchain.
So: what are you waiting for?
Read more →Extreme isolation part 3: coding a CRUD app (with full example)
CRUD apps start simple, yet often get messy and nasty really fast. They are a great test bed for Extreme Isolation.
I started a few months ago looking at a fresh new way of architecting web applications. I suggest you read parts one and two first.
The app I’ve been mainly working on using this new method is an online version of Sol Trader, which isn’t really a typical web application most people write. I’ve since applied this paradigm to a directory application called “Discover” I’ve been working on for the Trust Thamesmead charity, and I thought I’d share the results.
Discover is a much more traditional “CRUD style” application. The administrators define audiences for a local area (people who go to school, or want to find a job) and add places to a site, grouped into topics for that audience. For example, if you’re into music (the “music” audience) you might want to see places in the “music shops”, “gig venues” and “music video shoot locations” for a particular area.
The source code is fully open source. Trust Thamesmead have a great ethos: they would love other local areas to pick up the application and run with it. This also means that I can use the codebase as a demonstration of extreme isolation.
Let me take you through how it works.
The basic models: Audience, Topic, Place
Let’s have a look at the data representation for models first. Check out audience.rb:
module Discover
class Audience < Struct.new(:description, :slug, :topics)
def initialize(*)
super
self.description ||= ''
self.slug ||= sluggify(description)
self.topics ||= []
end
def sluggify(string)
string.downcase.gsub(/\W/,'-')
end
def with_description(new_description)
self.class.new(new_description, slug, topics)
end
def with_topics(new_topics)
self.class.new(description, slug, new_topics)
end
end
endThese objects are immutable. They are created from an AudienceRepository, which handles all the persistence of the objects for you. They know nothing about loading, saving or disk representations, which is exactly as it should be.
Audiences themselves are very simple containers of a description and a list of associated topics. They have a method to generate a slug, and two generator methods to create new audiences based on this topic: that’s how we handle updating audiences.
A web request to retrieve an object
The web logic is wrapped up in two files: a Sinatra application in app/audiences.rb which acts like a controller would in Rails, and a shared module in app/crud.rb which contains logic used by all the other Sinatra apps.
A web request comes in to the application and runs this code in the shared logic:
host.get '/:slug/?' do |slug|
@object = find(slug)
haml :edit
endThis find method is defined in the Audience-specific class:
def find(slug)
repository.audience_from_slug(slug)
end
def repository
@audience_repository ||= Discover::AudienceRepository.new
endThe AudienceRepository takes care of the persistence end of things (you can see how in persisted/audiences.rb), and returns back a plain ruby Audience object as shown above. This object is then passed to the edit.haml view file as @object and we’re done.
A web request to update the object
Updating the object is more interesting. The following action is called first, which then calls a series of other methods:
host.post '/:slug/?' do |slug|
candidate = find(slug)
queue = validator(candidate).
validate(update_from_params(candidate, params))
queue += editor(slug).apply(queue)
downstream(queue)
end
...
def update_from_params(object, params)
object.
with_description(params[:object][:description]).
with_topics([params[:object][:topics]].flatten.compact)
end
def validator(candidate)
AudienceValidator.new((repository.active_audiences - [candidate]).map(&:slug))
endThe first line retrieves a plain immutable Audience object as before. The update_from_params method is called next: this returns a new Audience object with the updated information, using the factory methods we defined on the model earlier.
Validation
The new Audience object is passed to an AudienceValidator object (defined here) which takes a list of existing slugs in the database, and returns one of two things:
- A
ValidAudiencechange if the newAudienceobject is valid - An
InvalidAudiencechange if it is not valid
We appear to be reinventing the wheel with the Validator object here: but the great advantage with doing things this way is that the object has no dependency on the database at all. This means it can be tested in isolation, it’s fast, and we can chain them together and reuse them in more situations.
Applying the changes
The queue of changes is then pipelined through various other services in true Extreme Isolation fashion. Firstly we apply the queue to an object we receive from the editor method call in the Sinatra application:
class Editor < Struct.new(:slug)
include Reactor
def valid_audience(change)
Changes::AudienceEdited.new(slug, change.audience)
end
end
def editor(slug)
Editor.new(slug)
endThis processes the ValidAudience change and returns an AudienceEdited change, which is tacked on to the end of the queue of changes. (See reactor.rb for exactly how the plumbing works.) An InvalidAudience change is ignored - we don’t want to edit the audience in this case.
The resulting change queue is then passed to downstream which is the set of services that process all web requests:
def downstream(queue)
repository.apply(queue)
AudienceHandler.new(self, '/').apply(queue).first
endThe AudienceRepository picks up the AudienceEdited change and does the correct thing to the persisted record. The AudienceHandler works out how to return the right message to the web interface. It handles InvalidAudience and AudienceEdited messages, as well as AudienceCreated and AudienceDeleted messages for the other CRUD operations.
Creation and deletion
The other CRUD operations work very similarly. The creation simply constructs a brand new Audience object, checks validity and passes the resulting set of changes to the AudienceRepository and the web handler. Deletion is even simpler: it just passes an AudienceDeleted message to the downstream method.
Extending the set of services
This way of doing web applications is extremely extendable. Here’s a much more complex downstream method for Sol Trader Online, which is run for every single player action web request in the game:
def downstream(queue)
queue = Solweb::OrderQueuer.new(@position).pipe(queue)
queue = Solweb::PositionPermissionChecker.new(@position, @game).pipe(queue)
queue = @position.pipe(queue, @game.turn_count)
queue += Solweb::GoalChecker.new.check(queue)
queue += Solweb::OrderChecker.new(@game.positions).check(queue)
queue += Solweb::MissionDealer.new(Solweb::MissionGenerator).apply(queue, @game)
queue += Solweb::Notifier.new(@game).apply(queue)
GameRepository.apply(@game.identifier, queue)
Handler.new(self).apply(queue).first
endEach piece is totally isolated and therefore easily testable. When one service gets too complex, it’s easy to split up what it’s doing into two services: PositionPermissionChecker is a recent extraction from the code inside the Position object.
Conclusions
This is still an experiment. It’s more involved that a typical CRUD app, and harder to get going, but the individual pieces (the validators, the Editor class, the Handler classes) are all very testable as they only do one thing in isolation.
There are also many ways that I could improve the web logic, but at the moment those classes are fine for my purposes. Likewise, all the javascript is still inline in the views, and has yet to be pulled out and refactored.
What do you think of the approach? Can you see yourself using it on your next project?
Read more →Extreme isolation part 2: separate the domain from the changes
I started a few months ago looking at a fresh way of architecting web applications. Since writing the first article in this series I’ve extended the codebase considerably and have a few more thoughts on how to take these ideas further. If you’ve not read it already, you probably want to go back and read the previous article first.
This time round, I discuss how I reduced the codebase dramatically by separating the full updating of the domain from the generation of change information. This refactor stemmed from two problems I had spotted in my code: an observation that some of my methods were doing too much, and the need for wrapper methods to preserve immutability.
Problem 1: methods doing too much
In Sol Trader: Online, each player has a Position within the game. I’m using the word “position” in the same way you’d talk about a chess position: it’s the state of the players involvement in the game.
In the previous article I was doing two things within each method in the domain that performed an action for game Position.
- Returning a new copy of the domain object modified to reflect the change
- Pushing a new object onto the
changesarray
For example, this particular method on a player’s Position allowed them to attack a target:
class Position
def attack(target, changes)
new_position = with_order(AttackOrder.new(target))
changes << CharacterOrderedToAttack.new(new_position)
new_position
end
endAs well as calling with_order to create and return a new Position with an AttackOrder, I’m creating a CharacterOrderedToAttack change, adding the new position to it, and adding that to the changes array.
Problem 2: container objects needing wrapper methods
This was problematic enough, but it was exacerbated by the fact that the position was only one of a list of positions within a Game object, so in order to keep the Game immutable, I had to have a Game#attack method to wrap the new position returned within a new game, using code something like this:
class Game
def attack(position, target, changes)
self.class.new(positions.map do |current_position|
if current_position == position
position.attack(target, changes)
else
current_position
end
end)
end
endI abstracted much of this out to helper methods, but I was deeply unhappy about having to have a method on the Game object for each action I could apply to Position.
A mistaken assumption: that I actually need this object
The reason for writing all this code to return a new copy of the object with the changes applied rested on the assumption that I was actually going to need this object to finish processing the request.
After a close look at the calling code in the web logic, it turns out that I didn’t need it at all - I only ever operated on the changes that were returned in the array. Therefore, why was I bothering to generate it?
post "/attack/:target" do |target|
changes = []
new_game = game.attack(current_position, target, changes)
GameRepository.apply(changes)
WebResponder.apply(changes)
# new_game is never used!
endIf I don’t bother to return the updated game object, I can reduce the code for the attack method to a one-liner which simply returns a change. Now my domain logic was back to just doing one thing:
def attack(target, changes)
CharacterOrderedToAttack.new(with_order(AttackOrder.new(target))
endI didn’t then need Game#attack at all, so that method could be safely deleted.
This one insight, when propagated through the system for all the existing actions, reduced the size of the codebase by about 10%.
In making this change, I’ve moved entirely to a version of the Command Query Reponsibility Segregation (CQRS) pattern. My regular domain is entirely read only, and only used for querying the data, and my domain for updating the model is based on lightweight change objects, which are passed to services to update persistence and handle web requests.
Next time
Changes can cause other changes: Next time, I plan to talk about how I’m feeding changes back into other services, to allow reactions to certain behaviour.
Read more →Extreme isolation in web apps: part 1
I’ve been hard at work on a web based prototype for Sol Trader recently in order to test some game mechanics ideas.1 I’ve been building the web app in a slight different way to the normal process I use to build web software, and it’s high time I started talking about it.
The examples are written using Sinatra as the web layer and MongoDB as the persistence layer, but you could use any web framework, persistence mechanism, or language for that matter, to express the same concepts. In fact, that’s really the point.
Step 1: Classic Ruby web app design
When I originally started up the project. I threw up a few different Mongo persisted objects to get myself going:
post '/join/?' do
@game = Game.last
@character = Character.new(:name => params[:name], :account => @account)
@joining = Joining.new(:character => @character, :game => @game)
begin
@character.save!
@joining.save!
flash[:notice] = "You have joined the game successfully."
redirect '/game'
rescue Mongoid::Errors::Validations
flash[:error] = "There was a problem creating the character and joining the game."
haml :join
end
endThis is pretty typically how I’ve organised my self in the past when writing an app: I’d have a Game model, and a Character model, and I have a Joining model to link the two together. These objects responsible for handling their own persistence. I’m using Mongoid, but this could just as easily be ActiveRecord. Here’s the joining model, for example:
class Joining
include Mongoid::Document
include Mongoid::Timestamps
belongs_to :character
belongs_to :game
endStep 2: Extracting the behaviour from the action
When thinking this over, I realised that there were entirely different concerns going on here:
- I’m creating a relationship between a new character and the game that they’re joining,
- I’m persisting that relationship in a database,
- I’m responding to the result of that process in my web app.
Time to seperate some of those concerns from the web layer. Following Graham Ashton’s excellent recent blog post2, I decided to introduce CharacterCreator and GameJoiner class to the procedings to improve the join action. Here’s the CharacterCreator class (the GameJoiner is similar):
class CharacterCreator < Struct.new(:name, :owner, :repository)
def perform(reporter)
character = repository.new(:name => name, :account => owner)
if (character.save)
reporter.character_created(character)
else
reporter.character_creation_problem(character.errors)
end
end
endHere’s the action which uses it:
def character_created(character)
@character = character
end
def character_creation_problem(errors)
flash[:error] = "There was a problem creating the character: #{errors}"
haml :join
end
post '/join/?' do
creator = CharacterCreator.new(params[:name], @account, Character)
creator.perform(self)
if (@character)
joiner = GameJoiner.new(Game.last, @character, Joining)
joiner.perform(self)
end
endInstead of the logic existing entirely inside the action itself, the logic has been moved into a seperate class, which calls back into the app class to make the changes that are required. This removed most of the logic from the action at the bottom, and allows us to test the CharacterCreator in isolation without having to fire up the whole web app.
Step 3: Extreme isolation: separating arrangement and work
So far, so good: but it’s not perfect. The persistence is still very much embedded inside the character class, and it’s necessary to use mocks for testing. I wanted to see how far I could push the tests without needing to use mocks at all, as they are sometimes a code smell for tight coupling. This means that you need to completely avoid callbacks, use dependency injection throughout and rely on passing simple structures between your methods. This means I couldn’t use a Publish/Subscribe model either: I wanted to see just how far I could take isolation and code decoupling.
So how about disconnecting characters and games from the persistence mechanism entirely, and just using a queue to communicate between them?3
Character = Struct.new(:name, :account_id)
Game = Struct.new(:characters)
post '/join/?' do
changes = []
character = Character.new(params[:name], @account.id)
game = GameRepository.latest.join(character, changes)
GameRepository.apply(changes)
self.apply(changes)
endThis is quite a departure. Let’s take each line of the new action in turn.
After creating an empty array to store a set of changes, we then create a character, which is defined as a simply ruby Struct.4 We then grab the latest game and call join, which represents the actual work of the class. Game#join is defined as follows:
def join(character, changes)
if has_character_with_name?(character.name)
changes << JoiningError.new("A character with that name already exists.")
self
else
self.class.new(characters + [character]).tap do |game|
changes << CharacterJoined.new(game)
end
end
endNote that we’re not changing the object here: we are treating the game object as immutable. We instead create a new copy of the object and then return it. We also return a change object and add the new copy of the game object to it. This is all domain logic: there’s no mention of any implementation details.
The apply method is very simple. it loops through the changes asking them to perform an operation on the current object. Depending on the type of the change, this will call a different method on the object:
def apply(changes)
changes.each { |change| change.effect(self) }
end
...
class JoiningError < Struct.new(:message)
def effect(caller)
caller.joining_error(self)
end
end
class CharacterJoined < Struct.new(:game)
def effect(caller)
caller.character_joined(self)
end
endWe’ve now built a generic handler for the different things that can happen when a join is performed. As long as we include the apply method in our controller object, and define the joining_error and character_joined methods, we can handle a joining change in any other object. The apply mechanism shown here can easily be abstracted away so we don’t have to worry about it.5
Handling the changes
There are two subsystems I want to be able to handle a joining change: the game repository (so that it can save the new character to the database), and the web action itself (so that we can show the relevant page to the user). Both these systems are at the ‘edges’ of the system, whilst the game object sits in the middle. This turns out very similar to the “Ports and Adaptors” or “Hexagonal” approach Matt’s been talking about recently.6 It also has similarities to the Actor model of concurrency used in Erlang.7
The GameRepository defines the relevant methods like this:
def character_joined(change)
save(change.game)
end
def joining_error(change)
endNote that the joining_error isn’t interesting to the GameRepository class, so we don’t do anything with that message.
And the web action in our Sinatra class defines them like this:
def character_joined(change)
flash[:notice] = "You have joined the game."
redirect_to '/game'
end
def joining_error(change)
flash[:error] = "There was an error when joining: #{change.message}"
haml :join
endThe result
We have now seperated the arrangement of the operations which need to be performed (the saving, rendering web pages, joining games) from the work itself: they are all completely and totally isolated from each other. This has a number of advantages:
- The web action and repository steps can be performed independently from each other, and neither cares about the implementation of the other.
- The join method in the plain ruby game object cares nothing for its own persistence, and knows exactly zero about web applications, which is just as it should be. It’s like putting your systems in solitary confinement, with no access to the outside world.
- It’s easy to build in another handler here - perhaps to update a web socket for a JavaScript client side app - by simply applying the changes to a new subsystem object:
WebSocketServerperhaps. - Having Cucumber documentation hitting the web app was very useful as I made bigger changes, as I could still verify that everything was working. This gave me courage to proceed with something a little different.8
- There’s nothing to stop me making the queues proper
Queueobjects, and start running the system in parallel in future, to take advantage of multiple cores.
The verdict
I love working in this way. It’s very freeing not having to think about persistence or web apps when trying to reason about complex domain concepts. It scales well, too: I’ve now built most of the protoype using a form of this approach. The domain logic is about 1,000 lines of code, my entire persistence layer still sits in one 200 line file, and the main web app is another 200 line file. These files are manageable because there isn’t much going on in them: they’re just handling lots of different types of changes by defining a few methods. In fact the real GameRepository class has a lot of lines which look like this:
alias_method :character_ordered_to_travel, :save_position
alias_method :character_ordered_to_mine, :save_position
alias_method :character_ordered_to_join_fleet, :save_position
alias_method :character_ordered_to_attack, :save_positionWhat do you think of this approach? Is it an improvement, or does it just obfuscate logic? I’d be grateful for feedback.
More to come
Next time I plan to talk about how I’m performing more complex operations by feeding changes back into the domain to allow reactions to behaviour. Stay tuned!
-
Sol Trader is the space trading and piracy game I’ve been writing for the last year or so. The online version I’m describing in this post will be available at http://online.soltrader.net once it’s ready. ↩
-
Refactoring with Hexagonal Rails is an excellent post by Graham Ashton on how he cleaned up controller actions whilst working on his Agile Planner software. ↩
-
I am indebted to Gary Bernhardt’s Separation of Arrangement and Work screencast at Destroy All Software for the inspiration that led to the final step in this refactoring. ↩
-
Ruby structs are a convenient way to create simple classes to store values. ↩
-
In the real system this all exists in Modules. I’m only showing it long-hand here for clarity. ↩
-
This is probably the most comprehensive post on the subject: there are also many links in the first post in Matt’s series. ↩
-
Read more about the Actor Model here. ↩
-
See my previous post for some examples of how I’m writing the Cucumber features for this project. ↩
Features are documentation, not tests
Cucumber features are primarily documentation, and only incidentally tests to execute.
However, it’s easy to fall into the trap of writing features which don’t actually read like documentation at all, but a long, tortuous, and highly repetitive mess of tests.
The problem
Here’s an example of a feature that’s difficult to read.
Feature: User adds a task to a project
As a user I want to add a task to a project, so that I can track
what's left to do on the project.
Scenario: User adds tasks
Given a user called "User"
And a project called "Project"
And the user "User" has permission "Task managment" for the project "Project"
When I add a task "Task" to the tasks list of the project "Project"
Then the task "Task" should be listed on the task list of the project "Project"I’ve written many scenarios like this in the past: I’m sure many of us have. What’s wrong with it?
It doesn’t read like English
Scenarios like this are easy to code, because all the information you need is right there. However, they don’t read well: they are very repetitious in their use of language and are difficult to scan. They don’t read like English.
In my experience, those who are the best at coding are often the worst at writing features. They tend to think of steps like code and apply good coding principles to them. For example, they try to reuse steps as much as possible (the DRY principle), and give steps all the information they need to run (the Dependency Injection principle).
This sounds sensible, but it leads to poor scenarios and poor step code in practice. Steps are not method calls, and shouldn’t read like them.
The whole point of Cucumber is that we get the ability to use natural language to make our features easier to understand. Writing a feature in this way is akin to writing this blog post in the following style:
“If I kept mentioning the feature when discussing the feature with my audience, my audience will get bored with the fact that I kept mentioning the feature when discussing the feature with my audience, and my audience as a result of getting bored will lose interest in the feature that I keep mention when discussing the feature with my audience…”
Nobody speaks or writes like that! The key difference is that we use context when we communicate to people. We use shorthands such as ‘it’ to refer to someting that we’ve just discussed, and we constantly assume a huge amount of knowledge on the part of our listeners.
Using member variables in step definitions helps give context
When I’m tempted to be too repetitous and start writing my features like test code, I start using member variables to capture what the current state is my steps (I’ve written about the pros and cons of this before: see the article linked at the end of the post.) As long as you are judicious with your member variables and don’t let them get out of control, they can make your features much easier to read. Let’s restate the previous feature using context:
Feature: User adds a task to a project
As a user I want to add a task to a project, so that I can track
what's left to do on the project.
Scenario: User adds tasks
Given a project called "Project"
And I'm signed in as "User"
And I have permission to add tasks to the project
When I add a task to the project
Then the task should be added to the projectMuch easier to read. Here’s what the steps might look like:
Given /^I'm signed in as "(.+?)"$/ do |name|
@user = User.new(name)
end
Given /^a project called "(.+?)"$/ do |name|
@project = Project.new(name)
end
Given /^I have permission to add tasks to the project$/ do
@project.add_permission_to(@user, "Task management")
endOnce you are freed from needing to refer to the domain objects you are using in every step, you are able to write your feature in pretty much the way you want to, and you can make them into true documentation, not matter what your audience.
Reading like a game manual
If we’ve now got the tools to make our features more flexible, then how about we try and make them true documentation that’s useful to our end users, not just our stakeholders?
For example: currently I’m in the process of working up a web prototype of some of the game mechanics on Sol Trader, a game I’ve been working on for the last year. The aim is to quickly iterate on the core simulation: it’s hard to do anything quickly in raw C++.
In order to document these game mechanics for my beta testers, I could have sat down and written a long markdown file, but instead I decided using the cucumber features themselves to describe the behaviour that I want to capture. I’ve used the preamble to write my “acceptance criteria” in prosaic format so that someone new to the game will be able to undrstand how to play. The scenarios are written as specific examples of game behaviour that still reads like a manual.
Here’s an example feature of a character joining a fleet:
Feature: Joining other characters' fleets
A character that is travelling to another location is vulnerable
to attack from pirates. If you wish, you can choose to join a
character's fleet as they travel to bolster their defences against
any attack that they might come under. You will also participate
in any attacks they might make against pirates.
You choose to join travelling characters through meeting them in
the Spaceport Bar, or by contacting them on the Comms Channel
should you be in open space. Once you are in a character's fleet,
you will stay with them until they leave the location, and you
will travel with them to their destination. You can choose to stop
being in the fleet at any time.
...
Scenario: You can't join a fleet when someone is in the middle of a travel order
Given you are playing Eddie
And you are in Earth Orbit
And Terry travelled to Mars Orbit a turn ago
Then you won't be allowed to join Terry's fleetI’ve chosen here to reverse the normal “Given I do this” and instead use “Given you do this” - it feels more like a game manual when I write the feature like this.
Hopefully it’s clear enough to understand, assuming you had some context about travel orders. Let me know what you think.
Stories that are specific but not soporific
Using a tool like Relish, which allows you to publish your features to a website, is a great way to ensure that the documentation that your project is producing is actually readable over time. When forced to read your features as documentation on a website, rather than as “code” in your text editor, you immediately start seeing ways that they can be improved.
The more interesting we make our features to read, the more likely people will read and update them.
A challenge for today: pick one scenario on your project and read it out loud to a non-technical co-worker. If they don’t get a sense of what the scenario is describe, try and rework it until they do.
Further reading
-
Should we store state in our steps: a blog article I wrote last year discussing the pros and cons of member variables in steps.
-
Sol Trader: the space trading and piracy game I’ve been writing for the last year or so. The online version will be available at http://online.soltrader.net once it’s ready.
-
Relish: a great tool for getting your features published in a non-technical format. Full disclosure: I train with the creator of Relish at BDD Kickstart, but although I don’t personally benefit from Relish. It’s a great tool though, you should use it.