Last month at Cherrypick we launched a brand new meal generator that uses LLMs to create personalized meal plans.
It has been a great success and we are pleased with the results. Customers are changing their plans 30% less and using their plans in their baskets 14% more.
However, getting to this point was not straightforward, and we learned many things that can go wrong when building these types of systems.
Here is what we learned about building an LLM-based product that actually works, and ends up in production rather than languishing in an investor deck as a cool tech demo.
You Do Not (Usually) Need an LLM
The first and most important step is a product one, not a technical one. Before diving into using LLMs, think carefully about whether you need one for the problem you are solving.
It is critical to make sure you have a problem that:
- uniquely benefits from an LLM’s capabilities,
- has an interface that matches how users want to work,
- can be run economically enough that it is sustainable, and
- can have the LLM’s drawbacks mitigated.
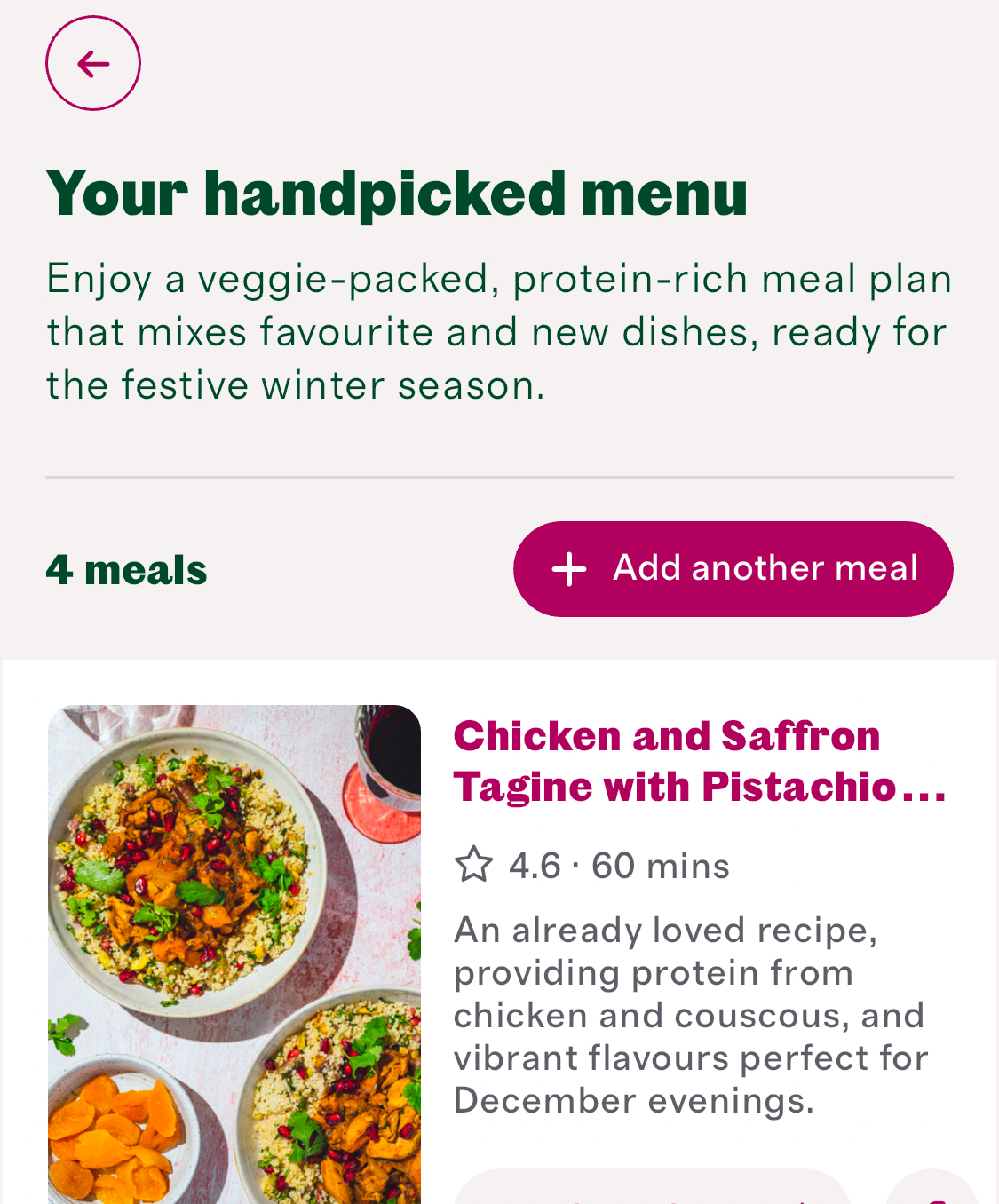
We have had a meal generator in Cherrypick’s app since early 2023. It allowed customers to pick a number of meals they wanted for the week, and we would generate a plan for them. They could “reject” a meal and ask for another, but there was no way of specifying which meal they would prefer.
We wanted more personalisation, and we wanted to explain to customers why we made the choices we did when selecting recipes for their plan. LLMs gave us a great opportunity to show personalised reasons why we had selected a set of recipes for them. It would have been difficult to get this kind of impact using another method.
LLMs excel at tasks requiring natural language understanding, creative generation, and complex pattern recognition. They are overkill for simpler problems that could be solved with traditional programming or basic ML approaches.
Regular expressions might suffice for extracting structured data from text. Traditional ML classifiers could work better for categorizing content into predefined groups. Templates with variable substitution are often enough for generating repetitive content. Rule-based systems are more reliable and cheaper when making binary decisions.
LLMs are most appropriate when you need complex natural language understanding, creative content generation, contextual reasoning, or handling of ambiguous and novel situations.
For our meal planning feature, we needed the model to understand dietary preferences, combine compatible recipes, and generate natural explanations - tasks that clearly benefited from an LLM’s capabilities.
Find the Right Interface
If you have decided you need an LLM’s unique benefits, the next thing you must discover is the ideal way for customers to interact with your system.
The first instinct of most teams building with LLMs has been to build a chatbot. Resist this urge. Chatbots seem like the obvious choice for LLM applications as the usage mode directly maps to how the underlying models are presented and we inevitably associate LLMs with ChatGPT1.
It is important to remember that LLMs started out as completion interfaces. We have been using them for completion in our product since 2022 for our recipe uploader. Chat is a specific use case, not the only way of using them. There are often better ways to solve the customer problem than a chat interface.
The interaction model of chatbots often feels unnatural for many common tasks. Chatting works well for open-ended discussions, and therefore naturally lends itself to customer support interfaces for example. However, it can feel forced and cumbersome for more structured interactions.
Another issue with chatbots is that users experience fatigue from the constant need to type messages and engage in back-and-forth conversations. This creates friction in the user experience that can lead to decreased engagement over time. It is interesting that many LLM interfaces have moved away from chat, using multiple choice selections exclusively with chat as a fallback.
This is exactly what we chose to do for our meal generator. The process of generating a plan and then tweaking and improving it is a natural back-and-forth interaction that does not require constant typing from users. Customers can reject a meal with a pre-defined set of options, that are generated by the LLM along with the plan. That way these options feel customised and natural.
Calculate Costs Ahead of Time
Another reason not to use chatbots is that they typically require multiple LLM calls for each interaction as the conversation progresses. These costs can quickly add up. If you are building for a consumer app, this is a problem. Typically you have a large number of users and are charging a small amount per user, which can make the cost of LLM calls unviable.
We experimented with chat-based grocery tools in 2023. We had a proof of concept that allowed customers to add groceries to their basket via WhatsApp. It worked well and was fun and quick to use. However we realised that to provide a good service we would need to make hundreds of calls per shop, which would have entirely eroded our profit margin from that shop.
A meal generator is significantly more cost-effective for a customer that a grocery chatbot. It requires only a few LLM calls per meal plan generation, versus dozens of messages in a typical chat session. The limited number of meal plans a customer will generate each week makes it financially viable.
Whatever you are building, budget for LLM calls as part of your initial investigation. Try and understand the number of tokens you will need to generate for each user interaction and how many interactions will be needed per billing cycle.
LLM calls are still expensive enough that you need to carefully consider their cost. While prices have dropped significantly, they remain an important factor to budget for.2
Work With the Model’s Randomness
A big hurdle for any new LLM based system is their unpredictable nature. Many developers initially try to force these models into producing deterministic output all the time. This is a mistake, as LLMs are inherently fallible.
Instead of fighting against the model’s variability, we learned to work with it. The key was providing the right context. For us, this meant carefully curating what we sent to the LLM.
We could have given the model a full list of recipes and asked it to select the best ones based on the customer’s diet and goal preferences. This could have caused many problems if the model made mistakes, selecting recipes that were obviously wrong, or (worse) choosing recipes that were harmful for the customer to eat.
To get around this, we did not send the model the full list. Instead with each prompt we send the customer the details of only the recipes the customer can actually eat. This avoiding wasting tokens on recipes that should never be selected.
We explored avoiding using the prompt, and instead use tools (previously called function calling) to find particular types of recipes and returning filtered results for the customer. We eventually chose to use the prompt as it is quicker and cheaper - only one LLM call is required. This means larger prompts with more tokens, but it works reliably for our use case and gives us confidence in the system’s effectiveness. The disadvantage is that we can only send a subset of recipes in order to keep the token count manageable. This is a random set at the moment, but we are working on improving this.
Build a Robust Evaluation Framework
Even when we mitigated randomness, we still needed to ensure consistent quality of results. We also needed to be able to compare models to see which could provide the best results for the least cost. We built a multi-layered evaluation system to manage this. For more on how to do this, see Eugene Yan’s excellent eval articles and Hamel Husain’s definitive guide on building LLM Judges.
Our first line of defense was automated validation. We verified perfect JSON structure in all responses and checked recipe IDs against our provided context to ensure they were not hallucinated by the LLM. When generations failed, our system automatically retried the plan. At the moment we are getting a 25% failure rate, which means one or two retries are needed for each meal plan generated. As only only LLM call is required per plan or change, we decided this was an acceptable level of speed and cost.
The next evaluation layer was expert review by a person. Our Head of Food Sophie assesses a sample of generated plans for quality and nutritional balance. She looked at flavor combinations and ensured the meals would work well together over the week. This helps maintain high standards that automated checks alone could not guarantee.
All evaluations were stored to build training data for future improvements. We kept version of our templates for A/B testing and tracked success metrics for each variation. Regular prompt refinement, based on this accumulated feedback, helped us continuously enhance the system’s performance.
We did not want to wait for enough data to try new prompts and models, so we used templated prompts to re-run our meal generations for new prompts and models easily. By using Liquid templates for our prompts, it was straightforward to continue to include the same data in each prompt run, whilst tweaking the prompt text to improve the output.
This produces a verifiable set of results, although it takes a lot of human involvement at the moment. The next steps are to use LLMs to automate the process of both running evaluations and improving the prompts. We have thousands of generated plans stored along with automatic and expert evaluations, so it is now possible to prompt an LLM with sufficient examples to learn how to both evaluate plans and improve prompts.
LLMs are powerful tools if used in the right way. Too many applications are poorly thought through and end up becoming cool demos for investor decks or just another chatbot.
Do not let this stop you. If you have a problem that benefits from LLMs, where you can mitigate the inevitable drawbacks, and you can design the right interface and cost model to make it work, then you can create the future.
-
The association between LLMs and chat interfaces is extremely strong; so much so that the principle API interface for them from OpenAI is styled as a chat interface. I think this is a blinkered approach that only considers one type of solution. This has unfortunately become the standard for most models and therefore requires developers to map their use case to this interface. ↩
-
As of December 2024, the cost of running a powerful LLM is still a few dollars per million tokens and returns full results in tens of seconds. This is too slow and expensive for many consumer applications. ↩
More articles
Kill Your Prompts: Build Agents That Actually Work
Every technical team I talk to faces the same painful truth about AI agents. They build something that works brilliantly in their demo, showing it off to stakeholders who nod approvingly. Then they deploy it to production and watch it break in ways they never imagined. The carefully crafted prompts they spent weeks perfecting become a maintenance nightmare.
Recently I showed a (virtual) room full of technical leaders how to kill their prompts entirely. I do not mean improve them or optimise them. I mean kill them completely and build something better.
Read more →Master Prompt Stacking: The Secret to Making AI Code Like You Do
After months of fighting with inconsistent AI coding results, I discovered something that changed how I work with tools like Cursor. The problem was not my prompts. The problem was that I had no idea what else was being fed into the AI alongside my requests.
During a recent webinar, I walked through this discovery with a group of engineers who were facing the same frustrations. What we uncovered was both obvious and surprising: AI coding tools are far more complex than they appear on the surface.
Read more →The Huge List of AI Tools: What's Actually Worth Using in June 2025?
There are way too many AI tools out there now. Every week brings another dozen “revolutionary” AI products promising to transform how you work. It’s overwhelming trying to figure out what’s actually useful versus what’s just hype.
So I’ve put together this major comparison of all the major AI tools as of June 2025. No fluff, no marketing speak - just a straightforward look at what each tool actually does and who it’s best for. Whether you’re looking for coding help, content creation, or just want to chat with an AI, this should help you cut through the noise and find what you need.
Read more →Unlocking Real Leverage with AI Delegation
Starting to delegate to AI feels awkward. It is a lot like hiring your first contractor: you know there is leverage on the other side, but the first steps are messy and uncertain. The myth of the perfect plan holds many people back, but the reality is you just need to begin.
The payoff is real, but the start is always a little rough.
Here is how I do it.
Read more →How I Make Complex AI Changes
Most technical leaders know the pain. You get partway into an ambitious AI project, then hit a wall. You are not sure how to start, or you get so far and then stall out, lost in the noise of options and half-finished experiments.
Recently I tackled this head on. I did this live, in front of an audience. I used a framework that finally made the difference.
The challenge: could I take a complex change, break it down, and actually finish it, live on stream? My answer: yes, with the right approach. Here is exactly how I did it.
Read more →