I’ve recently set up several CI Joe instances to handle our various projects at Eden. We’ve been using Integrity for several months, but it’s caused us a few problems and I yearned for something simpler. CI Joe is about as simple as it gets, and the brevity of the code encourages hacking and customisation.
I’ve now set it up to run multiple Joes using Rack and Passenger for the various different projects we run. Being as I didn’t find much on the net about setting up CI Joe in this way, I thought a fairly detailed howto would be helpful. Let me know how you get on with it.
Folder structure
Our structure looks like this:
/var/www/rails-apps/
cijoe/
project1 # symlinked to ../cijoe-repos/project1/public
project2 # symlinked to ../cijoe-repos/project2/public
index.html # the front page of your CI site.
cijoe-repos/
config.ru # Master config.ru: see below
build-hook # Build hook file: see below
credentials # username/password for the build-hook POST
project1/
config.ru # symlinked to ../config.ru
app/ # contains the actual git clone'd app
public/ # empty: only there for Passenger
project2/
etc.Our index file is simply a javascript redirect to our dashboard app, which I mentioned here but will discuss more thoroughly in future posts.
Passenger config
The main Passenger vhost is set up for the cijoe/ directory, and each CI Joe installation has to be symlinked in this way for it to pick them all up.
We put the following file in /etc/httpd/sites.d/ci.conf:
<VirtualHost *:80>
SetEnv PATH /usr/local/bin:/opt/ruby-ee/bin:/bin:/usr/bin
DocumentRoot /var/www/rails-apps/cijoe
RackBaseURI /project1
RackBaseURI /project2
PassengerMaxInstancesPerApp 1
PassengerMaxPoolSize 2
ErrorLog logs/ci-error_log
CustomLog logs/ci-access_log combined
<Directory "/">
AuthName "Eden Development CI"
AuthType Basic
AuthUserFile /var/www/rails-apps/integrity/app/htpasswd
require valid-user
</Directory>
SetEnv RAILS_RELATIVE_URL_ROOT
</VirtualHost>The key bits here are as follows:
- Passenger by default runs ruby processes without a path set, so set the path so CI Joe can call git correctly.
- RackBaseURI is used to start multiple Joe’s, one for each project.
- PassengerMaxInstancesPerApp needs to be set to one, otherwise you’ll get weird results.
- Set your PassengerMaxPoolSize to exactly the number of Joes you’ve got running, so Passenger doesn’t kill the build processes.
- Clear the RAILS_RELATIVE_URL_ROOT environment variable: this will be set by the RackBaseURI calls, and will bleed into your tests, break any that rely on absolute paths.
config.ru
The config.ru we’re using for the individual Joes is as follows:
# Required so that we can set path correctly for Config, which
# is loaded statically due to a bug in cijoe
$project_path = File.dirname(__FILE__) + "/app"
require 'cijoe'
# setup middleware
use Rack::CommonLogger
# configure joe
CIJoe::Server.configure do |config|
config.set :project_path, $project_path
config.set :show_exceptions, true
config.set :lock, true
end
run CIJoe::ServerWe keep this in the cijoe-repos/ folder, and symlink it into the different project folders. We also apply a monkey patch to the run_hooks method to strip out backticks: these can stop the hooks running correctly.
Build hooks
If you want to use our build hooks, read on, otherwise you can safely skip the next section.
We have one master build hook script living in cijoe-repos/ which we symlink everywhere. This reads the file structure to find out which project we’re in, and its own symlinked name to work out what’s happened. It then HTTP POSTs the results to our dashboard application:
#!/bin/bash
FULLPATH=`cd $(dirname $0); pwd`
echo $FULLPATH >&2
PROJECT=`echo $FULLPATH | awk -F/ '{print $(NF-3)}'`
STATUS=`echo $0 | awk -F- '{print $NF == "worked" ? "pass" : ($NF == "reset" ? "building" : "fail")}'`
PW=`cat $FULLPATH/../../../../credentials`
curl -u $PW -d"author=$AUTHOR" -- http://ci.edendevelopment.co.uk/dashboard/build/$PROJECT/$STATUS
echo "Project: "$PROJECT", Status: "$STATUS", Fullpath: "$FULLPATH >&2It’s not very pretty: my bash-fu isn’t up to much. Suggestions for improvement are welcome.
credentials
The credentials file mentioned above is a file which lives in cijoe-repos/. It has one line in it:
username:passwordThese are the user authentication credentials for the POST to your dashboard.
Adding a project
To add a project to the structure:
cd cijoe-repos
mkdir -p project/public
cd cijoe
mkdir -p /path/to/cijoe-repos/project/public project
cd project
git clone git@github.com/path/to/my/project.git app
ln -sf ../config.ru
# If you're using hooks:
ln -sf /var/www/rails-apps/cijoe-repos/build-hook app/.git/hooks/build-worked
ln -sf /var/www/rails-apps/cijoe-repos/build-hook app/.git/hooks/build-failed
ln -sf /var/www/rails-apps/cijoe-repos/build-hook app/.git/hooks/after-resetThen you need to poke the apache vhost configuration to add another RackBaseURI and up the number of processes by 1.
Conclusion
This setup works well for us. We’ve only been running it a few days, but it does feel cleaner and more manageable that the old Integrity system. It’s nice to have each server in seperate processes, with a fully customisable dashboard distinct from the build servers themselves.
With this setup a project could even choose to run a different server: as long as a config.ru file was defined and the HTTP POST notifications are made correctly, it will all work the same way.
I’d love to make it a bit less complex to set up new projects. If you have any ideas for how to improve the setup then do let me know!
More articles
Why I ditched all the build tools in favour of a simple script

Build tools are wonderful and impressive constructions. We developers invest colossal amounts of time, effort and code into their creation and maintenance.
Perhaps a lot of this work is unnecessary.
On Sol Trader, by ditching the complex dependency checking compilation system I was doing in favour of a simple homegrown script, I cut my build time from several minutes down to 5 seconds.
I’m not talking about continuous integration tools such as Jenkins, but tools such as CMake, Boost.Build and autotools. Perhaps these build tools are white elephants? They require endless maintenance and tinkering: does this outweigh their actual usefulness?
Incremental compilation: the end of the rainbow
One of the main aims of a compilation tool is to allow us to divide all the pieces of a system up into component parts to be built individually (another main aim is portability, which I’ll address below). This allows us to only build the part of the code which changed each time, and link all the compiled pieces together at the end.
However every time we build a source file, we have to grab a piece of code, grab all the dependencies of that code from disk. The disk is probably the slowest thing in our machines, and we have to grab everything from disk every time, for each source file we’re building. If we’re building a lot of files, this can get very slow.
The second problem with this is when we change an often-reused piece of code, such as a header file, we have to compile the whole lot again. In order to cut the amount of things to build down, we can set up complex dependency management systems to try to limit the amount of things built. We can also set up a precompiled header which tries to minimise disk access by building a lot of the code in advance for us, but more and more of our time is handling the side effects of pushing for an incremental build system.
Trying to get a build tool set up is like searching for a pot of gold at the end of a rainbow, which gets further away no matter how much effort we put into finding it. Even when it’s working, it’s not that fast, and it requires constant tinkering to get it right.
How I build code now: the Unity build
How about instead of building incrementally, we build everything every time? Sounds counter-intuitive, doesn’t it? It’s actually faster, easier to maintain, and doesn’t require setting up a complicated build tool.
We create one Unity.cpp file. This includes all the C files and headers that I wish to build. We build that one file each time, and then link it with the 3rd party libraries. Done. It takes about 3-4 seconds to run, or 10 seconds on the Jenkins server.
Now, when I change a header, the script just builds everything again, so it doesn’t take any long that a few seconds to see the effects of any change I want to make.
Caveats
“Strategy is about making choices, trade-offs; it’s about deliberately choosing to be different.”
– Michael Porter
There are a few caveats with Unity builds that we should be aware of:
One compilation unit means no code isolation
The static keyword will stop working as we expect: we won’t be able to constrain variables and methods to one file any longer. The power of good naming helps us out here. We also have to be disciplined about keeping our code modular and not referring to code that we shouldn’t.
We still need to discover platform-specific properties
On an open source project which must be built everywhere, we’re never going to get away with something as simple as this: we’re going to need to check to see what headers exist and which libraries are available.
However, there’s no reason we can’t set up make to do a simple unity build such as this one.
Also, many of these portability problems we patch over with our build tools stem from the fact that our code wasn’t correctly written to be portable in the first place. Also, many build systems still in wide use today have a lot of cruft left over from the 1980s - do we really still need to check for the presence of <stdlib.h>?
Additionally, in the case where we can control our build environment, it becomes even easier: we simply create a build script for each compilation platform we need to support (a build.bat for Windows, for example).
Sol Trader’s Unity build setup
This is my current build setup for Sol Trader in its entirety.
#!/usr/bin/env bash
MACOSX_DEPLOYMENT_TARGET=10.6
CC=clang++
EXE=sol
CFLAGS=" -DGLEW_STATIC -DSOL_SLOW -DCURL_STATICLIB -DNDEBUG -D_GNU_SOURCE=1 -D_THREAD_SAFE -g -O0 -I.. -I../src -I ../lib/include -I ../dist/build/include -I../dist/build/include/boost -O0 -I ../dist/build/include/freetype2 -I ../dist/build/osx/include -I ../dist/build/osx/include/SDL -Wall -Werror -Wno-unused-private-field -Wno-unused-variable -Wno-missing-braces -mmacosx-version-min=10.6 -F../dist/build/osx/frameworks"
LIBS="../dist/build/osx/lib/libSDL_mixer.a ../dist/build/osx/lib/libvorbis.a ../dist/build/osx/lib/libogg.a ../dist/build/osx/lib/libvorbisfile.a ../dist/build/osx/lib/libyaml-cpp.a ../dist/build/osx/lib/libRocketCore.a ../dist/build/osx/lib/libRocketControls.a ../dist/build/osx/lib/libRocketDebugger.a ../dist/build/osx/lib/libfreetype.a ../dist/build/osx/lib/libpng15.a ../dist/build/osx/lib/libboost_system-mt.a ../dist/build/osx/lib/libboost_filesystem-mt.a ../dist/build/osx/lib/libboost_thread-mt.a -l SDL_image -l SDLmain -l SDL -L ../dist/build/osx/lib ../lib/libcurl.a ../dist/build/osx/lib/libz.a -Wl,-framework,Cocoa -Wl,-framework,OpenGL -headerpad_max_install_names"
set -e
set -x
mkdir -p build
pushd build
$CC $CFLAGS -c ../src/Unity.cpp -o Unity.o 2>&1 | sed 's|../src|src|'
$CC $CFLAGS -o ../$EXE Unity.o ../src/main.cpp $LIBS 2>&1 | sed 's|../src|src|'
date
popdThis is working fine for me right now. It’ll need expanding on in the future, but instead of spending endless time screwing with my build system now, I’m actually adding game features instead.
Want to hear the other side of the debate? Here’s a well-argued opposing point of view: the evils of unity builds.
Read more →The toolchain of dreams
Seems like yesterday people were saying that it was difficult to host Ruby apps. It was around the time people were saying “Rails doesn’t scale”, which thankfully has been proved dramatically wrong.
For a while now Ruby apps have been unbelieveably easy to run and host, especially when you’re getting started.
But it’s got even better than that in the last few months. I’ve now got a complete Continuous Delivery toolchain set up for my latest app, entirely in the cloud. It’s Continuous Delivery As A Service, and it’s dreamy. This is how to set it up, and how it works.
Source control: Github
I’m using Github for code hosting and source control. You probably are already too. Most of the other services integrate with it very well, so setting this toolchain up is so much easier if you’re using it.
Build server: Semaphore
Cloud-based build services have been running for a while now. I like Semaphore - the user interface is clean and easy to read, and it does automatic deploys of passing code:
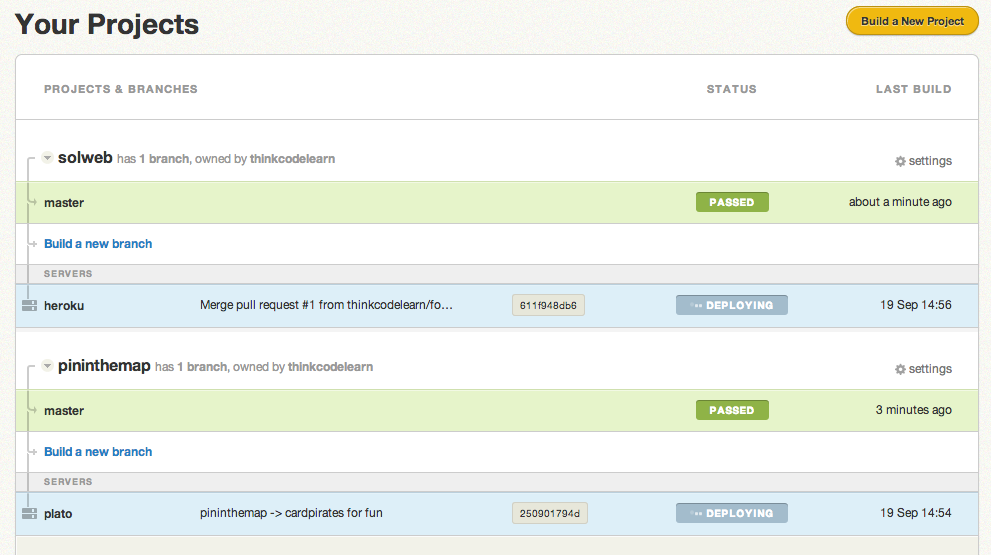
Set up Semaphore by creating a trial account, connecting it with your Github account and picking the repository you’d like to build. It automatically analyses your project for a build script so if you have a standard Ruby or Rails project you probably won’t need to configure it much.
Deployment: Heroku
If you’re using Heroku to deploy your code, set it up to deploy to Heroku. It takes a few seconds in the settings menu for your project to do so. You can also make it use a Capistrano deploy script.
Quality Analysis: Code Climate
Lastly, set up Code Climate to monitor the quality of your app’s code. Setting up Code Climate is similar to Semaphore: sign up for a trial, connect to Github, select the repository. It will automatically set up the Github commit hooks for you.
To get code coverage integration, you’ll need to install a gem, but it only takes a few minutes.
How the toolchain works
Out of the box, Github tells Semaphore to build every commit I push. If I push a branch, Semaphore builds that, too, and updates the build status of the commit so that everyone can see if the pull request is ready:
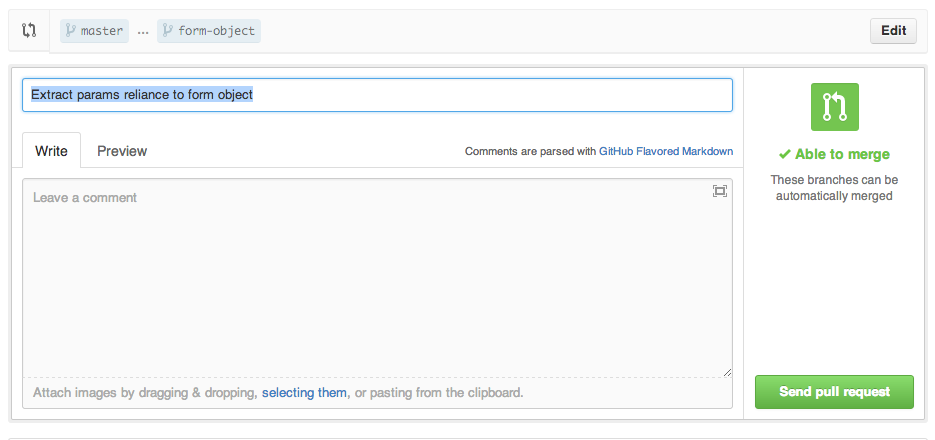
Merging code into master
When the pull request is merged, the code goes into master:
- Semaphore builds the master branch. If the tests pass, the code is deployed to Heroku.
- Code Climate automatically gets notified by Github and checks to see whether coverage has improved or decreased, whether I’ve introduced any Rails security problems, or whether my code is bad:

Logging
Builds, deploys and Code Climate notifications are all automatically posted to Hipchat, so I get a log of everything that’s happened without being inundated with emails:
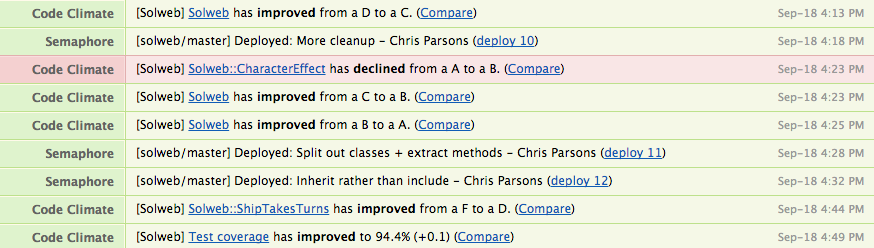
Just set up a Hipchat account, get a Room API key from the settings page, and plug that into Github, Code Climate and Semaphore. Done.
The dream toolchain
This is how you use this toolchain:
$ git pushEvery time I push some code, it’s checked carefully, and monitored for quality and security holes. The tests are run and coverage reports are generated and presented nicely. If all the tests pass the code immediately gets deployed to production, and all of this activity is reported and logged in one central place.
This is the future. It really doesn’t get much better.
Time is valuable: and this didn’t take long
This took me about 40 minutes to set up. 30 minutes of that was fiddling with the settings of the various tools: but actually leaving them all set to default does the right thing for me in all cases. Most of the tools simply connect to your Github account to set up all the access controls and keys for you.
The cost
For one project, this incredible toolchain will cost you the following:
- Github: $7 a month for the micro plan
- Semaphore: $14 a month for the solo plan
- Code Climate: $24 a month for the solo plan
- Hipchat: Free for one room
- Heroku: Free for a one dyno app.
That’s $45 a month. That’s next to nothing for such an amazingly powerful toolchain. Plus if you run more than one project, the per-project cost decreases dramatically.
I used to run one server to host one Rails app for $140 a month, for years, with no build server, deployment or code metrics built into the toolchain. Today I pay half that for a much more sophisticated setup.
Admittedly, the hosting costs with Heroku will go up once your app becomes popular, but this is a good problem to have, and at that point you shoud have the cash to invest in a chef-based cloud server deployment solution. I run one of those for an old SaaS service I run to keep costs down. It’s still very easy to connect a different deployment strategy in to this toolchain.
So: what are you waiting for?
Read more →Use Markdown to send HTML email via Mutt: now working on iOS mail
A technical configuration post this time around. If you’re a fan of the Mutt command line email program then read on…
For a while I’ve been writing HTML email using Markdown, on the odd occasion I feel the need to format my emails. I’ve followed the instructions on this site and it’s been working to great effect: except in one specific case.
If you also attach a regular file to the email, as well as the HTML output, the text2mime-sendmail.pl script provided stuffs the attachments into the same multipart/alternative section. Many email clients can figure this out and display the attachments anyway, but crucially it seems that iOS mail can’t, which means that you either only see the attachment, or you only see the HTML without an attachment.
In order to fix this, I rewrote text2mime-sendmail.pl in Ruby: the original Perl was doing manual text processing, and it seemed to be a good idea to use a proper mail library. I used the Mail library in Ruby to parse the email and send it out with the attachments outside the multipart/alternative block.
The full issue is described here - I think it’s a bug in iOS Mail rather than anything else.
So, if you’re using the approach referenced above to send HTML email in Mutt, you might want to switch to my script, or modify your scripts to do a similar thing so that your emails are still readable in iOS Mail. Good luck!
Read more →